
1. GPU 基本架构
GPU 可以类比 CPU 架构理解,只不过弱化控制器,强化计算能力 (SP),如下图:
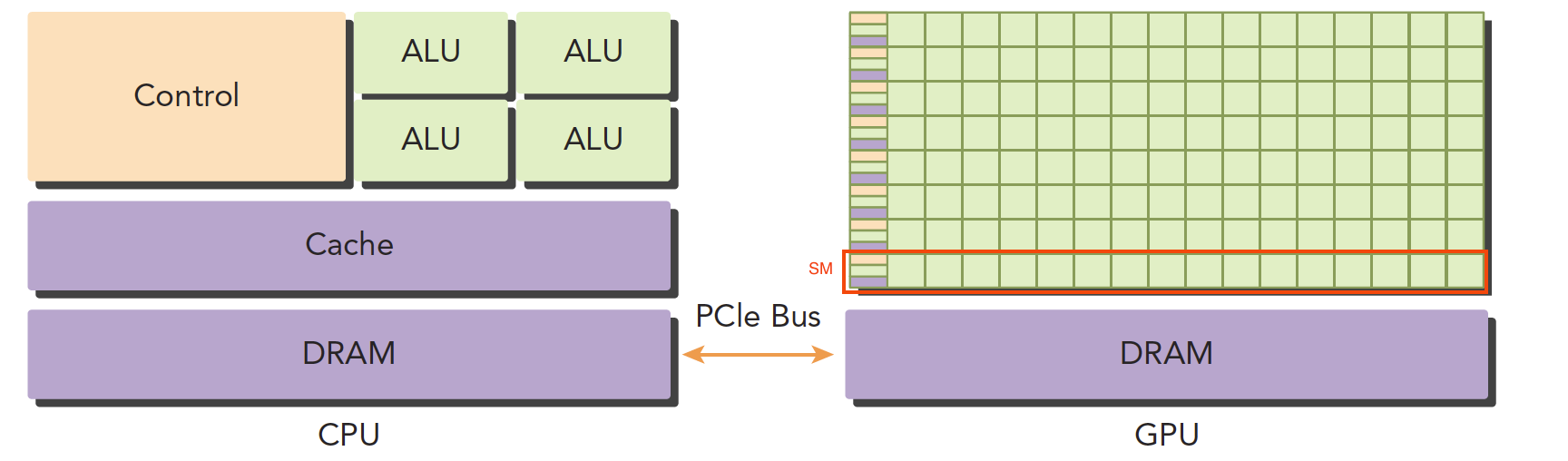
右图 GPU 中,绿色方块为 SP (streaming processor) 是 GPU 运算的基本单元 (其实就类似 ALU),GPU 中天然的将多个 SP 组合在一起,配合一定数量的寄存器和共享内存,形成一个 SM (streaming multiprocessor) ,使其在架构上对 SIMD 更加友好 [个人理解: SM 是 GPU 对 SIMD 支持的基本单元],这都是很直觉的内容。
我们学习的 CUDA Runtime API 相对 CUDA Driver 更高层一些,CUDA 部分由 NVCC 编译器负责编译,所谓核函数,就是 CUDA Device 上运行的代码。
__global__ 说明符会被 NVCC 编译器识别区分为核函数 (Kernel),为了实现从主机端向设备端发起核函数调用,CUDA C++ 扩展了标准语法,引入了执行配置(Execution Configuration)。该机制通过三尖括号 <<<A, B>>> 设定,其中 A 是 block nums, B 代表 thread nums,即:
1 | void func<<<num_of_blocks, num_of_threads>>>() |
那么总共分配的线程就是:num_blocks x num_threads 个
说了这么多,来手写一个 CUDA Hello World 吧
1 |
|
注意,显然我们这是异构计算,GPU 的计算是异步的,所以需要显示的调用 cudaDeviceSynchronize 来等待 GPU 调用完成,不然 CPU 的程序会直接结束,详情可参考 api官方说明
输出结果:
1 | 主机启动:准备 GPU 调度, |

说些什么吧!