我们以“自顶向下”的顺序,逐层解析 nano-vllm 的实现细节,这一节将详细解析 用户接口层 的实现细节。
example.py
我们从使用体验出发,先主动思考下,如果是你来做一个推理引擎,当输入 prompts 后,应当发生些什么:
- prompts 转为可用的 tokens:首先当然是把
List[String]结构化并分词后,转化为 token 对应的List[Ids]; - tokens 加入引擎调度器的任务队列:既然有了 tokens ,自然是准备开始推理了,做一个任务队列接受所有需要完成的任务是基础的设计思路;
- 引擎逐步驱动执行推理:只要任务队列还有任务,那引擎就应该在 while 循环里逐步驱动完成所有任务;
- 用户拿到 prompt 对应输出的 text 文本:推理完成后自然应该拿到对应文本。
相信大伙在大框架下想的步骤都大差不差,事实上,nano-vllm 也基本是这么做的,其中,第 1、4 步的部分代码是在用户接口层就能轻松实现的,第 2、3 步的具体实现则放在了引擎调度层等之下的部分 【这里划分是显然的,就不费口舌了】。
结构化 prompt
如果各位有尝试过将 QQ 机器人接入大模型聊天 API 的朋友,相信对这步不会陌生,很多时候我们在写机器人角色卡的时候,总是要指定各种 role,比如,


事实上,在大模型推理的时候,我们也是这么干的,所有的 prompt 都应当首先转化成一个 List[Dict] 类型,其中,Dict 应当是像我们上面 {role : content} 格式,role 用来声明身份(比如,user 代表用户的输入,system 代表系统的输入),content 则是对应的具体内容。
我们都知道,不同 LLM 训练时文本内容都是独特的,如果没有一个标准化的输入格式,那么写代码的人就得带上痛苦面具为各个模型定制化输入格式了,这在 2026 显然是不能忍受的,而且在通过标准化的格式内容后,模型能够更合理且标准地输出相关内容,其性能也能有所保证。
在具体代码中,我们使用 transformers 库中的 AutoTokenizer 来实现:
1 | import os |
代码里,我们首先 [{"role": "user", "content": prompt}] 把 prompt 按照我们上面说的要求整理好,然后使用模型特定的 tokenizer.apply_chat_template 转换成标准格式,那具体长什么样呢?我们完全可以开一个 Debug 看下:

1 | # 转换后 |
可以看到,用户的输入内容 (user) 在标准化后被 <|im_start|>...<|im_end|> 标记,而模型的输出 (assistant) 则是在 <|im_start|>assistant 后等待模型自己去补全 (因为我们设置了 add_generation_prompt=True,大家可以自行试试如果设置成 False 会怎么样 ) ;tokenize=False 的设置则保证此时 prompt 依然只是 Python str 而非 token ids,转换成具体 ids 的过程被延后到推理时再进行。
执行推理
example.py 剩下的部分就很直观显然了(也没剩下什么了),无非就是实例化生成 prompt 所需要的 取样参数 (SamplingParams()),输出结果而已:
1 | def main(): |
SampingParams.py
熟悉 LLM 基础结构的朋友应该知道,在根据 prompt 生成 token 的过程中,会有一些采样参数需要调整来确定:
- 如何采用 token (
temperature) - 何时停止生成 token (
max_tokens&ingore_eos)
这里的数据类文件就是定义了这些参数
| 参数 | 作用 | 备注 |
|---|---|---|
temperature |
缩放 logits:logits / temperature,影响采样的随机性 |
必须 > 0(不支持贪婪采样) |
max_tokens |
生成的最大 token 数,到达后强制停止 | 默认 64 |
ignore_eos |
设为 True 时,即使生成了 EOS token 也不停止 | 用于需要固定长度输出的场景 |
实例化的 SampingParams 类跟随相应的 prompts 被传入给 LLM 推理引擎中,并在将一个个 prompt 转换成 Sequence 的时候被拷贝走, 在最后 token 生成与选择的时候被使用,其中,temperature 参数是比较有意思的一个,我们会具体讲讲。
Temperature
在模型最后一层,LM Head(通常为就是一层 FC)负责将 Hidden States 映射到词汇表大小的向量空间:
*设当前时刻的隐藏层向量为 $h\in \mathbb{R}^d$(其中 d 为模型的隐藏层维度),LM Head 的权重矩阵为 $W\in \mathbb{R}^{|V|\times d}$(其中 $∣V∣$ 为词汇表的大小)。*计算得到的输出向量 z 称为 logits:
$$z = Wh \in \mathbb{R}^{|V|} $$
这 $∣V∣$ 维的连续向量包含了模型对每个可能词汇的概率(未归一化)。,logits 需要经过 Softmax 归一化换为真正的概率:
$$P(X_i)=\frac{exp(z_i)}{\sum_jexp(z_j)} $$
通常而言,我们会选择 Top-p Sampling 的采样方法,通过计算累积概率,并设置一个阈值 p ,截取累积概率达到 p 的最小 token 集合,来实现动态截取 token 的数量的目的。
当我们在 Softmax 引入 Temperature T 后,我们便有了缩放模型生成的原始未归一化的 logits 的能力,直接改变最终生成 token 的概率分布形态,更加主动的影响 token 截取数量。此时,新的公式如下:
$$P(X_i)=\frac{exp(z_i / T)}{\sum_jexp(z_j/T)} $$
可以看到,就是除以了一个 T,
- 当 T=1 时:
公式等同于标准 softmax 函数。此时不产生缩放干预; - 当 T<1 时(降低随机性):
将 logits 除以小于 1 的数值,会扩大 logits 之间的绝对差值。经过指数运算后,高分与低分之间的差异被呈指数级放大。概率质量会高度集中于排名靠前的 token。当 T→0 时,基本等效于 argmax 运算,系统将确定性地选择最高分 token; - 当 T>1 时(增加随机性):
将 logits 除以大于 1 的数值,会衰减 logits 之间的绝对差值。指数运算后的结果使整体概率分布被压缩并变得平缓,逐渐趋近于均匀分布。原本处于边缘位置、低 logit 的候选 token 会被分配到相对更高的采样概率,从而提高了统计上的不确定性。
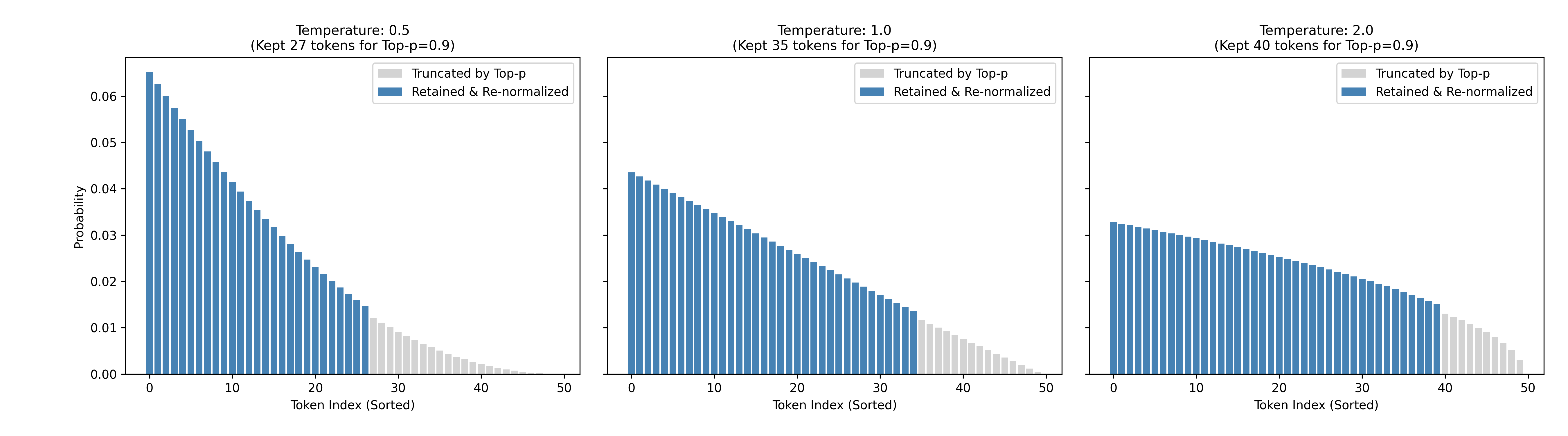
感觉还是有点抽象?我们来代码画个图直接展示下 T 的影响:
1 | import numpy as np |
代码如下图所示:
可以看到,随着 T 的增大,概率密度会越发平缓,使得最终保留的可选择的 token 数量会增多,从而最后在选择输出的 token 的时候,有更大可能选择其他 (相对尾部) 的 token。
Config.py
这个数据类就是一些基础的配置选项了,这里我们做一个简单介绍,等到具体使用到的时候再做详细的解释:
1 |
|
注意下,这里 max_num_bacthed_tokens 限制的是整个 batch 在推理的时候能够处理的 token 总量,而 max_num_seqs 限制的是 sequence 数量,目前大家可以简单将 sequence 理解为一条输入的 prompt。

说些什么吧!