
立志写出让呆呆兽都能看懂的教程讲解
KV-Cache … 是什么?
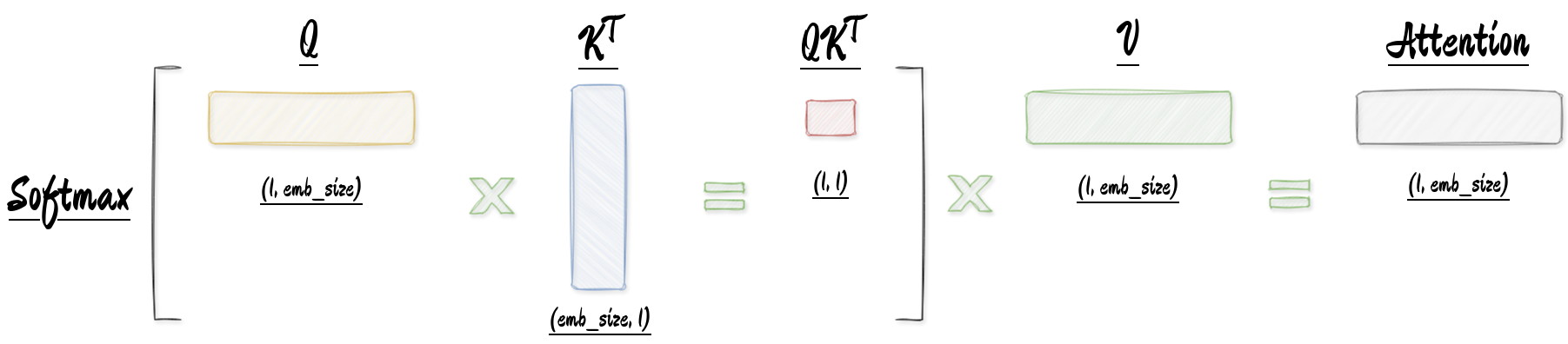
在回答这个问题之前,让我们先简单回顾下 transformer 的 decoder 中 attention 的计算
$$Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V $$
其中, $Q=XW_Q,\quad K=XW_K,\quad V+XW_V$,分别是输入序列对权重矩阵的线性投影。
如果各位还记得,在 decoder 架构中,我们引入了 causal mask 因果掩码 来 “隔断” 未来信息对过去信息的影响。
换句话说,模型在 token $i$ 处的 attention 输出仅取决于 token $[1, i-1]$ 的输入,而无法获取 $i+1$ 及其之后的位置信息。
正如下图展示的那样,对于 $t$ 位置的 $QK^T$ 计算,$t + 1$ 及以后的位置都会变成 负无穷$−∞$ ,如此一来这些被 mask 的地方在 softmax 后就会成为 0 :

现在,让我们继续计算第 $n + 1$ 个 token 的 attention 值,等等,你有没有发现一个惊人的事实:
以「我爱你」为例,假设**「你」是我们正在生成的新 token**。此时模型需要计算「你」这一行的 attention——也就是用「你」的 $q_3$ 去和所有位置的 $K$ 做点积,再加权求和 $V$:
$$h_{你}=\text{softmax}( \frac{ q_{你}\cdot \begin{bmatrix} k_{我}, k_{爱},k_{你} \end{bmatrix}^{T} }{\sqrt{d_k}} ) \begin{bmatrix} v_{我} \\ v_{爱} \\ v_{你} \end{bmatrix} $$
其中,$k_{我}, k_{爱},v_{我},v_{爱}$ 都是之前已经计算过的结果。换言之,当计算新 token 的 attention 时候,会重复使用上一个 token 计算出来的 K, V 矩阵!
那么,如果我们能够存储每个 token 计算产生的 K, V 矩阵的话,不就节省了大量重复计算的时间吗!真是机智如我 (当然,代价就是 内存/显存 大量占用)。这其实就是 KV-Cache,很简单吧。
但你是不是总觉得有什么不对?
还记得我们前面提到的一个 大前提 吗?causal mask 因果掩码?为何非要这个?如果没有这个难道就不能做 KV-Cache 了?
这个问题很有迷惑性,初想似乎可以,但实际上,我们来仔细分析下:
我们之所以能够缓存历史 token 的 K, V 向量,是因为在新 token 加入后,这些历史 K, V 向量保持不变。
我们把 token $i$ 在第 $l$ 层的 K 向量完整写出来:
$$k_i^{(l)}=x_i^{(l)}W_K^{(l)},\quad x_i^{(l)}=f(h_i^{(l-1)}) , \quad h_i^{(l-1)}=\sum_{j\in S_i} \alpha_{ij}v_j^{(l-1)} $$
可以看到,整个链路依赖的不变性在与集合 $S_i$ —— 即 token $i$ 在计算 attention 时能够看到哪些位置。
在有 casual mask 时,$S_i=\{ j\leq i\}$,是一个固定的集合,在加入新 token $t_{n+1}$ 后,对于历史位置 $i\leq n$,依然有:
$$S_i 不变⟹\alpha_{ij}不变⟹h_i不变⟹k_i,v_i不变 $$
而如果没有 casual mask,那么$S_i=\{1,...,n\}$,依赖整个序列,加入新 token $t_{n+1}$ 后,softmax 归一化会变成:
$$\alpha_{ij}^{old}=\frac{e^{s_{ij}}}{\sum_{k=1}^{n}e^{s_{ik}}} ⟹ \alpha_{ij}^{new}=\frac{e^{s_{ij}}}{\sum_{k=1}^{n+1}e^{s_{ik}}} $$
也即会发生:
$$S_i 变化⟹\alpha_{ij}变化⟹h_i变化⟹k_i,v_i变化 $$
之前缓存的 K, V 向量就彻底失效了,我们不得不对历史 $n$ 个 token 重新计算所有相关向量。

说些什么吧!