
立志写出让纯夏都能看懂的教程讲解
Scheduler
我们继续来解析“引擎调度层”的另一个重要角色:调度器 scheduler (废话,调度器能不重要)。
简单来说,scheduler 的功能是:在每一次 step() 推理时,决定让哪些 sequence 进入 GPU 执行计算,并且在显存不足时执行抢占功能。
从代码实现来看,scheduler 的思路很简单直接:
- 维护两个队列:
- waiting 队列:存储等待被执行 prefill 的 Sequence;
- running 队列:存储已经拿到 Block Cache 后续需要 decode 的 Sequence。
1 | class Scheduler: |
对于一条 Sequence 任务来说,它的生命周期基本是这样的:
1 | add_request() |
所谓人如其名,对于 scheduler 调度器而言,最重要的部分当然就是它的调度方法 schedule() ,我们在 3.1 节已经简单对这个方法做了解析。具体而言,它返回两个值:
scheduled_seqs:本步要送去执行的 Sequence 列表 list[Sequence]is_prefill:本步是 prefill 还是 decode 阶段
也就是说,Scheduler 每次调度只做一种模式:
- 要么这一步跑 prefill
- 要么这一步跑 decode
不会混着来。
prefill schedule
我们首先截取了关于 prefill 阶段的调度选取,在是否选择这个 sequence 进入 prefill 阶段中,会有几个简单直观的约束:
max_num_seqs:本轮 prefill 最多拉多少条请求进来;max_num_batched_tokens:本轮 prefill 的总 token 数不能太大,否则一次 forward 太重;can_allocate(seq):即使 seqs 条数、token 都没超,也可能因为 KV cache block 不够而不能接收这条请求。
通过简单约束后,对于每个 sequence,
- 为 sequence 分配 block:
self.block_manager.allocate(seq); - 统计真实计算的 token 数量:
num_batched_tokens += len(seq) - seq.num_cached_tokens。注意,如果前缀本身在 kv-cache 中,自然不需要重复计算,这里涉及到 prefix cache 的机制了,我们等后面回头再讨论。 - 状态切换:
seq.status = SequenceStatus.RUNNING,加入到 running 队列中。
1 | class Scheduler: |
decode schedule
在完全没有需要 prefill 的新请求后,scheduler 会选择 decode 的 seqs 进行调度:
当然,decode 也有一些类似约束,这里就不再重复了,我们这里只讨论一些比较关键的:
- 检查当前 seq 的 block 是否还能添加新的 token:
while not self.block_manager.can_append(seq):我们都知道 decode 阶段,每次step()都会往序列里写入一个新的 token,如果:- 当前 block 没有满,则直接写入即可;
- 如果当前 block 满了,则需要
block_manager为我们分配新的 block,倘若没有新的空闲了,则需要 scheduler 抢占,即:释放别的 sequence 占用的 block,给当前 sequence 腾出空间。
1 | class Scheduler(): |
抢占
抢占是 scheduler 实现调度的很重要的策略,保证了推理时 Sequence 的计算不会出现爆显存的危机:
在代码上:
1 | class Scheduler(): |
这里注意一个点:我们对于被抢占的 sequence,释放完显存后是重新返回 waiting 队首的,因为:
为什么是 prefill 呢?当然是因为我们已经将这个 sequence 的 KV-Cache 完全释放了,恢复自然得从 prefill 开始,毕竟巧妇难为无米之炊。
还有个小细节是这里的 while-else 结构,代表 else 下面的内容只有在没有发生 break 的时候执行。
1 | class Scheduler(): |
Block Manager
我们在 scheduler 中经常看见 block_manager 的身影,这玩意究竟是什么呢?从上面对 schedule() 的解析,我们好像知道:他能够为 sequence 分配管理需要的显存。
其实大差不差,block_manager 是 KV-Cache 的块管理器,实现了 Prefix Cache。
KV-Cache … 是什么?
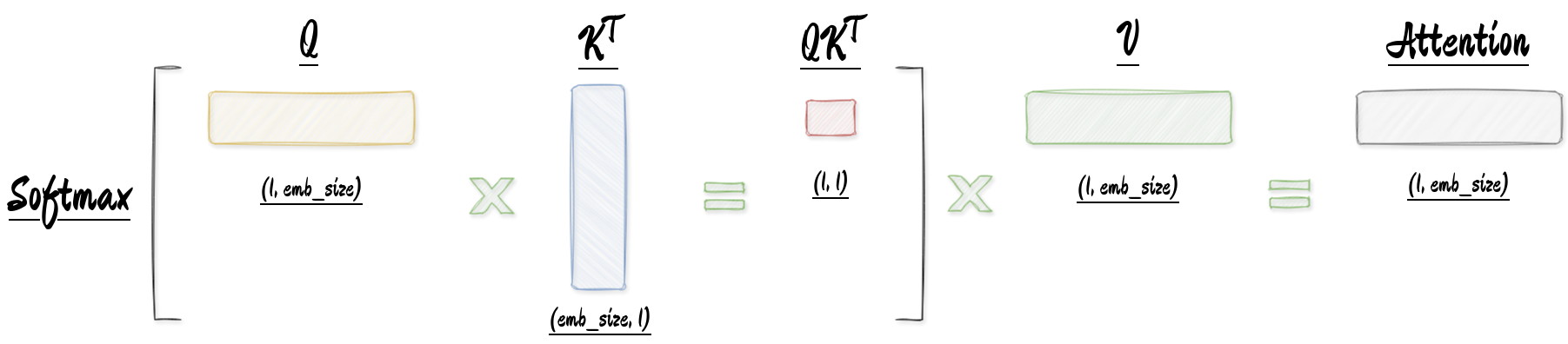
在回答这个问题之前,让我们先简单回顾下 transformer 的 decoder 中 attention 的计算
$$Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V $$
其中, $Q=XW_Q,\quad K=XW_K,\quad V+XW_V$,分别是输入序列对权重矩阵的线性投影。
如果各位还记得,在 decoder 架构中,我们引入了 causal mask 因果掩码 来 “隔断” 未来信息对过去信息的影响。
换句话说,模型在 token $i$ 处的 attention 输出仅取决于 token $[1, i-1]$ 的输入,而无法获取 $i+1$ 及其之后的位置信息。
正如下图展示的那样,对于 $t$ 位置的 $QK^T$ 计算,$t + 1$ 及以后的位置都会变成 负无穷$−∞$ ,如此一来这些被 mask 的地方在 softmax 后就会成为 0 :

现在,让我们继续计算第 $n + 1$ 个 token 的 attention 值,等等,你有没有发现一个惊人的事实:
以「我爱你」为例,假设**「你」是我们正在生成的新 token**。此时模型需要计算「你」这一行的 attention——也就是用「你」的 $q_3$ 去和所有位置的 $K$ 做点积,再加权求和 $V$:
$$h_{你}=\text{softmax}( \frac{ q_{你}\cdot \begin{bmatrix} k_{我}, k_{爱},k_{你} \end{bmatrix}^{T} }{\sqrt{d_k}} ) \begin{bmatrix} v_{我} \\ v_{爱} \\ v_{你} \end{bmatrix} $$
其中,$k_{我}, k_{爱},v_{我},v_{爱}$ 都是之前已经计算过的结果。换言之,当计算新 token 的 attention 时候,会重复使用上一个 token 计算出来的 K, V 矩阵!
那么,如果我们能够存储每个 token 计算产生的 K, V 矩阵的话,不就节省了大量重复计算的时间吗!真是机智如我 (当然,代价就是 内存/显存 大量占用)。这其实就是 KV-Cache,很简单吧。
但你是不是总觉得有什么不对?
还记得我们前面提到的一个 大前提 吗?causal mask 因果掩码?为何非要这个?如果没有这个难道就不能做 KV-Cache 了?
这个问题很有迷惑性,初想似乎可以,但实际上,我们来仔细分析下:
我们之所以能够缓存历史 token 的 K, V 向量,是因为在新 token 加入后,这些历史 K, V 向量保持不变。
我们把 token $i$ 在第 $l$ 层的 K 向量完整写出来:
$$k_i^{(l)}=x_i^{(l)}W_K^{(l)},\quad x_i^{(l)}=f(h_i^{(l-1)}) , \quad h_i^{(l-1)}=\sum_{j\in S_i} \alpha_{ij}v_j^{(l-1)} $$
可以看到,整个链路依赖的不变性在与集合 $S_i$ —— 即 token $i$ 在计算 attention 时能够看到哪些位置。
在有 casual mask 时,$S_i=\{ j\leq i\}$,是一个固定的集合,在加入新 token $t_{n+1}$ 后,对于历史位置 $i\leq n$,依然有:
$$S_i 不变⟹\alpha_{ij}不变⟹h_i不变⟹k_i,v_i不变 $$
而如果没有 casual mask,那么$S_i=\{1,...,n\}$,依赖整个序列,加入新 token $t_{n+1}$ 后,softmax 归一化会变成:
$$\alpha_{ij}^{old}=\frac{e^{s_{ij}}}{\sum_{k=1}^{n}e^{s_{ik}}} ⟹ \alpha_{ij}^{new}=\frac{e^{s_{ij}}}{\sum_{k=1}^{n+1}e^{s_{ik}}} $$
也即会发生:
$$S_i 变化⟹\alpha_{ij}变化⟹h_i变化⟹k_i,v_i变化 $$
之前缓存的 K, V 向量就彻底失效了,我们不得不对历史 $n$ 个 token 重新计算所有相关向量。
在了解了 KV Cache 的底层原理后,让我们再回过头来思考 block_manager 相关的代码。
作为 KV Cache 的内存管理器,我们已经知道它最大的功能就是管理每个 token 的 K, V 向量所需要的显存空间,可是该如何管理呢?这又是一个大问题。
纯夏:这不是很简单吗?一个 sequence 中所有 token 的 K, V 向量连续存在一起不就好了吗?

然而,理想很美好,现实却总是很苦感。如果我们按照简单的将同一个 sequence 涉及到的所有 token 的 K,V 向量简单按顺序排列存放,正如下图所示,我们会在显存占用上遇到几个很显然的问题:
- **外部碎片:**因为我们要求一个 sequence 中所有 K, V 向量在显存中顺序存储,而 sequence 的最终长度总是不确定的,使得系统在频繁分配和释放显存的过程中会将显存分割成多个小块,产生外部碎片;
- **内部碎片:既然总长度不确定,那如果我们总是对 sequence 申请最大支持长度的显存空间呢?**很显然,这会导致大量的显存内部碎片,因为实际 sequence 的总长度可能远远小于最大长度,这些内部预分配的空间就白白浪费了,而且还必须得等这个请求结束才能释放;
- **显存复用:**由于传统方案我们每一个 sequence 都独立顺序地存储 token 的 K, V 向量,在工程上,很难合理地使用那些重复 token 的 K, V 向量,我们不得不重复存储这些导致空间浪费。

等等,这些问题是不是很眼熟?
图片?
没错,在操作系统中,我们也遇到过几乎一模一样的问题,而操作系统提出的方法是:分页存储 (Paging),而 vLLM 也正是参考这一思路提出了适用于 KV Cache 存储方案的 PageAttention。
PageAttention
内/显存管理
在操作系统里,我们以 “页 Page” 为单位进行内存的操作和管理,在 vLLM 中,我们则是以 Block 为逻辑单位进行管理 (其实就是改个名字),每个 Block 都存储固定数量的 token 的 K, V 向量,如此一来,整个 sequence 所有 token 的 K, V 向量就被一个个 Block 管理了起来。
值得一提的是,同一个 sequence 的不同 Block 在物理上并不需要连续的排列放置,因为 vLLM 和操作系统一样,在 sequence 中引入了 block_table 作为中间层,抽象了整个寻址的过程来记录管理逻辑 KV Block 和物理 KV Block 的映射 (依然学习操作系统内存系统)。
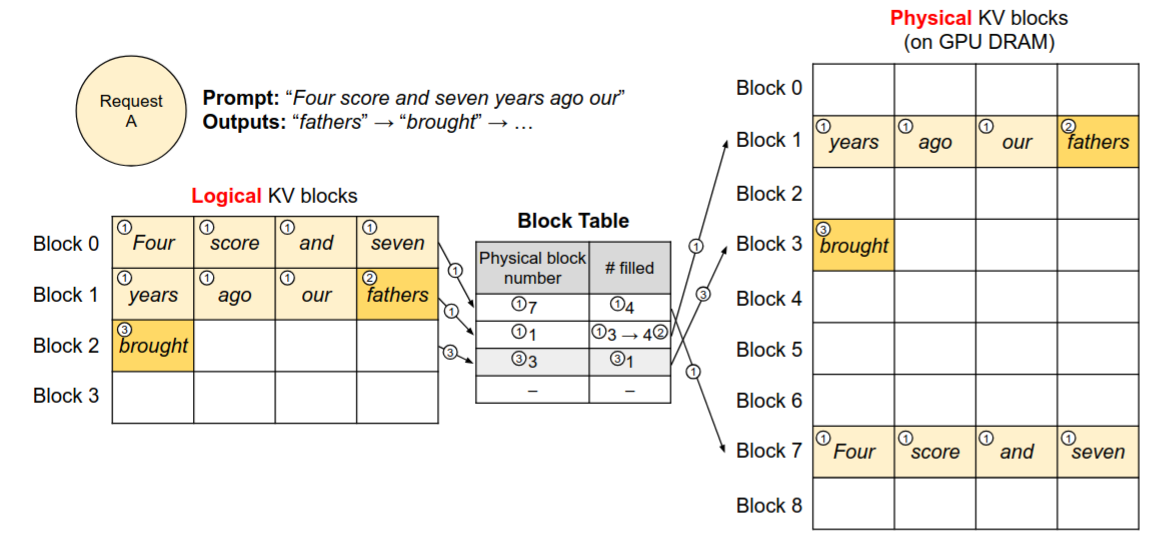
以下图为例,我们定义每个 Block 能存储 4 个 token 对应的 K, V 向量,因此前 7 个 token 被存储进了 Block 0 和 1 中,这两个逻辑 Block 经过 Block Table 映射到实际的物理显存 Block 1 和 7 中。
- 当完成 prefill 阶段,模型预测下一个 token 是 fathers,其 K, V 向量会存储进入 Block 1 的剩余位置中,并更新相应的 Block Table。
- 在 decode 阶段中,模型预测下一个 token 是 brought,由于 Block 1 已经存满,vLLM 会分配一个新的逻辑 Block 以存放 K, V 向量,更新 Block Table,并在物理显存中分配相应的空间。
整个机制和操作系统的内存分页大差不差,很显然,这种 PageAttention 使得我们能够:
- 消除外部碎片:只要物理块的总数足够,即使物理地址不连续,也可以通过映射表 Block Table 组合使用;
- 最小化内部碎片:显存浪费仅发生在序列的最后一个
block中。若block_size设为 4,则最大浪费仅为 3 个 Token 的空间,相较于传统预留数千个 token 的做法,空间利用率提升极其显著; - **高效空间复用:**我们能够以 Block 为单位去复用 token 的 K, V 向量,不仅可以用在由单一 sequence 分化所需的复用场景 (beam search),还可以用在多 sequence 有相同前缀 prompt 时所需的复用 (prefix cache)。
场景优化1:Parallel Memory Shared
This means that the KV cache of the same token appearing at different positions in a sequence will be different.
大家在用大模型的时候,肯定都会碰到这个场景:输入 prompt 后,GPT 同时生成两个 Output 以供你选择( 在早期 GPT 这个场景非常常见,进入 2026 后似乎少了,这是为什么呢 )。我们把这类 decode 策略称为 parallel sampling,即同一个 prompt sequence 输入,并行输出多个 output sequence 结果 。
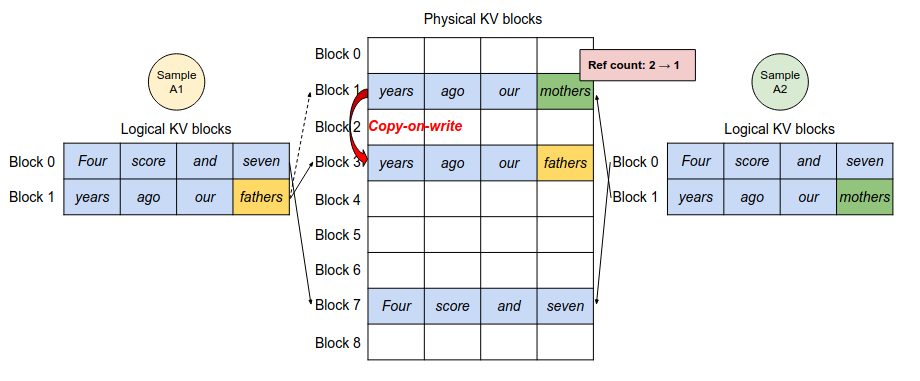
下图正好展示了刚提到的场景,两个不同的 output sequence 有着相同的 prompt tokens,而 PageAttention 将逻辑 Block 与物理 Block 分离的机制,很自然的支持我们能够共享这一块相同的 prompt KV Cache。两个 sequence 的 prompt tokens 虽然有各自的逻辑 Block 区域,但最终仍然实际映射到了相同的物理 Block,实现了共享 KV Cache 的目的。
既然多个 sequence 能够指向同一个物理 Block,那物理 Block 何时才能释放成为了一个关键问题。是不是又又很眼熟?想想 C++ 是怎么解决资源释放时机的问题?
是的,没错,shared_ptr 的引用计数。PageAttention 也是通过引用计数的方式很巧妙地解决了这个问题,当这块物理 Block 引用计数归 0 时,这块内存区域才会被回收释放。
共享内存是好的,但是如果共享的这个 Block 又恰好没有填满,下一个 token K, V 向量需要存储呢?现在多个 sequence 会指向相同的物理 Block,那我缺的存储空间这一块谁给我补呢?
既视感又又又来了?是的,没错,类似操作系统对 fork 进程的 Copy-on-Write (CoW) 机制,PageAttention 也做了相同的处理。
还是以图为例,得益于引用计数,当 A1 生成了 fathers 这个 token,并继续 decode 时需要将其对应的 K, V 写入到物理 Block 中,此时 vLLM 会**检查发现引用计数大于 1 ,**因此会复制一份新的物理 Block 内存区域以供 A1 Sequence 使用,并将原本的 Block 的引用计数减去 1 ;当 A2 想要写入新词 mothers 时,原本 Block 引用计数已经是 1 了,就不再需要 CoW,直接追加写入即可。
场景优化2:Prefix Cache
在场景 1 中,我们之所以能够共享物理显存,是因为所有的输出 sequence 实际还是来源于同一个 prompt。那么,如果我们有多个 Prompt,是否还有共享内存的空间呢?
答案是有的,而且很大。还记得我们在 第 2 节 提到过的结构化 prompt 吗?我们以“猫娘角色卡”为例,展示了用户输入自己的 prompt 后,大部分系统会做的事情:在用户 prompt 之前,加入系统专属的 system prompt,比如下面一大段的 “猫娘 prompt” 以帮助 LLM 更好的按照我们预定的逻辑输出回答。那么,尽管每次用户输入 prompt 都不同,我们总会有一段相同的 system prompt 作为前缀约束,这便为共享内存提供了优化的空间。因为 vLLM 将逻辑 Block 和 物理Block 分离的设计,在实际工程中我们可以很轻松地将重复使用这段 KV Cache (没错,又回到了场景1的优化实现)。

代码分析
经过了漫长的理论解析后,我们终于可以继续对 nano-vllm 的代码做进一步分析了。
我们很清楚知道,Block 是 vLLM 对于 KV Cache 显存管理的基本单位,它应当能够存储 N 个 token 的 K,V 向量,注意每个 Block 我们都会有个 hash 值,当为 -1 时表明这个 block 没有填满,否则已满,方便我们后续处理,并且也有引用计数帮助我们合理地释放空间:
1 | class Block: |
每一个需要执行的推理任务 Sequence 都有一个自己的 Block Table,记录了自身 token 的 KV Cache 的逻辑 Block Id 到物理 Block Id 的映射。比如一个 seq.block_table = [5, 12, 3] ,那么意味着,这个 Sequence 的 KV Cache 逻辑Block 0 对应 物理Block 5,逻辑Block 1 对应 物理Block 12,逻辑Block 3 对应 物理Block 3。
1 | seq.block_table = [5, 12, 3] |
那么我们如何为一个 sequence 分配管理这个映射表所需要的物理 Block Id 呢?
- 在
block_manager中,我们有allocate()方法。通过这个方法,我们会在 prefill 阶段对一个 sequence 所有的 token ids 分配其 KV Cache 所需要的空间。 - 那么,怎么实现我们前面提到的内存共享呢?
nano-vllm使用了 hash + dict 来帮助判断,一个新的 token ids 块在分配之前,会通过 O(1) 的 hash,来快速查出“这块内容是否被缓存过”。这里需要注意的是,同一个 token 出现在不同位置那么它的 KV Cache 也是不一样的,因此在计算 hash 的时候,我们会把 上一个 Block hash 的结果也作为输入一起计算,以避免出现问题。
1 | class BlockManager: |
- 在 decode 阶段,我们需要将每个新生成的 token 添加到 Block 中。
can_append()和may_append()就是干这事的。scheduler 会在调度 decode 阶段的 seq 时调用can_append()判断是否有足够的 Block,它会根据当前 token 是否是新 Block 的第一个来判断,如果是则说明需要分配一个新的 Block来给这个 token;如果不是,则不需要新 Block。may_append()则是真正为这个 token 分配空间 (如果需要)。
1 | token 位置(% block_size): |
1 | class BlockManager: |
- 对于 已经完成计算 和 被抢占 的 sequence,我们自然是要释放它所有的 blocks,
deallocate()方法实现了这个功能,它在我们系列文章讲过的scheduler中被调用。当然,正如我们上文理论分析的一样,只有引用计数归0,空间资源才会被真正释放。
1 | class BlockManager: |

说些什么吧!