
立志写出让纯夏都能看懂的教程讲解
我们继续自顶向下学习 nano-vllm 的架构,本章我们主要解析其自带支持的 qwen3-8b 的模型结构。本章我们主要解析其自带支持的 qwen3-8b 的模型结构。我们将首先介绍 qwen3 的模型结构,然后从代码入手快速学习了解整个前向推理过程,至于具体的基础算子实现我们放在后面再讲。
模型架构
先简单对 Qwen3 模型有个概念,整体其实很好理解,就是一个 Decoder-Only 的模型,每个 Decoder 层都有:
- RMS Norm + Attention:这里 Attention 是 Group Query Attention,顾名思义,就是多个 Q 头会对应相同的 K, V 头; 比较特殊的是,在具体计算 QKV 时,会对 Q, K 做 per-head 的 RMS Norm 归一化;
- RMS Norm + MLP:这里做了个相较于普通的直接两层 Linear,使用了门控网络来让模型自己学习动态选择特征的能力,并且用 SiLU 做激活函数,整体思路比较 intuition。当 gate 值接近 0 时,SiLU 接近于 0,代表该特征被抑制,反之,当 gate 很大,SiLU 接近于 gate,该特征值正常通过。
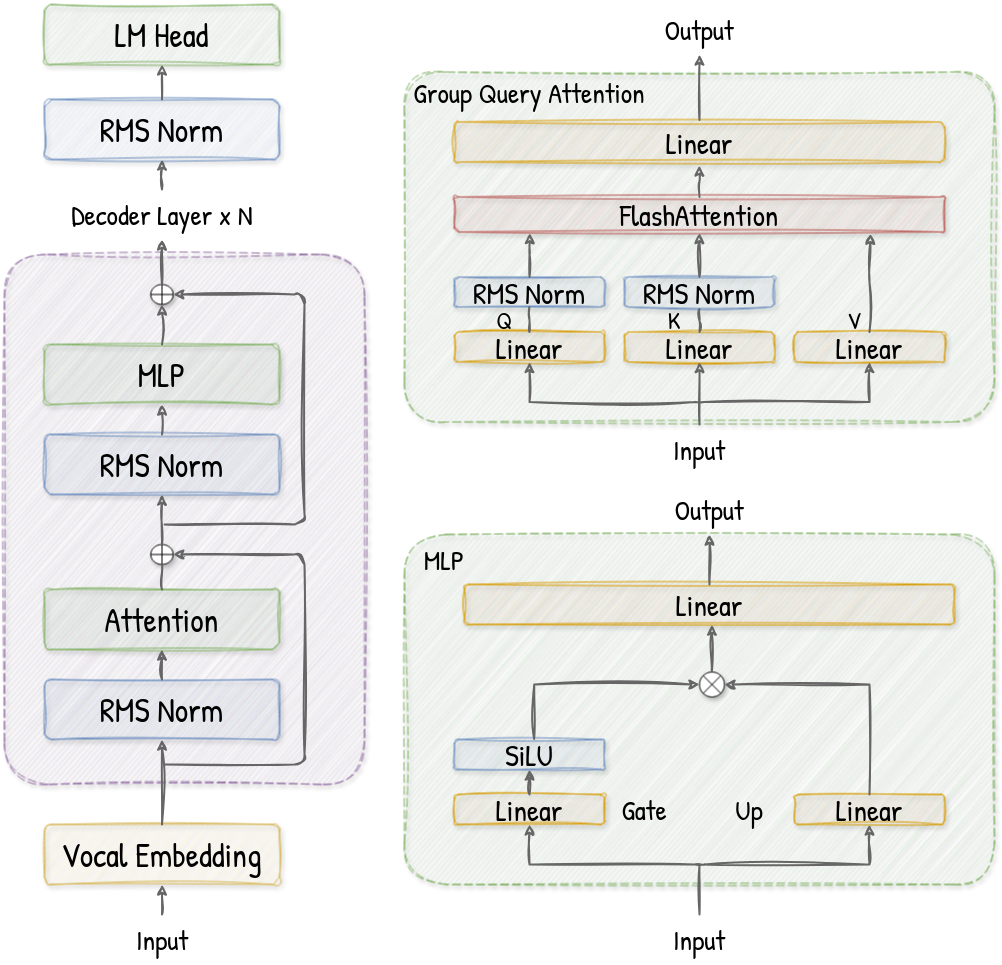
我们在 qwen3.py 的代码里,可以很直接的找到上面这个模型结构对应的代码细节。接下来,我们将继续自顶向下的顺序,对代码进行讲解,并在其中适当地掺杂原理解析。
Qwen3ForCausalLM & Qwen3Model
Qwen3ForCausalLM 就是 ModelRunner 使用的接口类了,封装了我们上面图画的整个 Qwen3Model 模型结构,包括词嵌入层、多个解码器层和最终的 RMSNorm 层。注意下,LM Head 和 Qwen3Model 是分开的,Qwen3Model 这个类可以看作是一个通用的特征提取器。
Qwen3Model 这个类实际上就是我们上图模型的拼装:
- 首先,
VocabParallelEmbedding将 token ids 转换为 word embedding,这是一个 [vocab_size, hidden_size] 大小的矩阵。为了支持多卡并行加速,所以我们很自然能够想到将这个 embedding 矩阵按行切割,平均划分个多卡进行张量并行,每卡只负责一部分内容,此时维度 [vocab_size / tp_size, hidden_size]。【你可能要问,那多卡并行的时候,token_id怎么知道要从哪个卡里获得对应的 embedding 呢?这个问题我们留到下章讲解。】; - 然后,
Qwen3DecoerLayer堆叠的 layer 将处理 embedding,和上图一样,每个 decoderLayer 都包含一个 self-attention 模块和一个 MLP 模块; - 最后,
RMSNorm对最终的hidden_states进行归一化。
1 | class Qwen3Model(nn.Module): |
Qwen3Attention
继续拆解 Qwen3Model 模块,根据上文描述,它是由 Qwen3Attention 和 Qwen3MLP 组合实现的。
Q,K,V 计算本身很简单,就是一个 Linear 层映射,这里为了充分利用多卡张量并行,我们在 QKVParallelLinear 的实现里将 Q,K,V 的矩阵映射计算合并在了一起计算,合并后的 Q K V 权重形状为 $(num\_heads \times head\_dim + num\_kv\_heads \times head\_dim \times 2, hidden\_size)$ (Pytorch 按照 [Output Size, Input Size] 存储,F.linear(x, W) 计算的时候权重矩阵会转置 x @ W.T ) 的线性层,这个矩阵在计算的时候,会按照转置后列平均切分给多卡并行计算,合并后输出就是 $[Q, K, V]$ 矩阵;
在 Multi-Head Attention 计算完后,我们通常会有一个 Linear 层,将多头的维度重新压缩回 hidden_size 的大小,这一层 Linear 的维度是 $(hidden\_size, total\_num\_heads \times head\_dim)$。同样的道理,为了充分利用多卡张量并行,我们在 attention 计算完后的 Linear 层也是类似的处理:按照转置后行平均切分给多卡做并行计算,各个卡计算完成后 all-reduce 通信求和获得完整的输出。
Qwen3 模型比较特殊的一点在于,其计算完 Q, K 后引入了 RMSNorm 进行归一化。
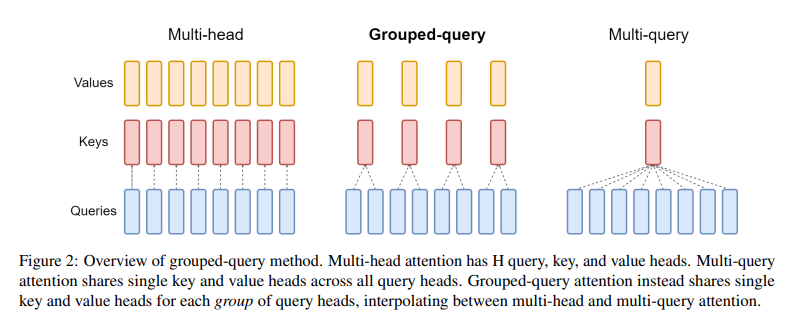
Group Query Attention
在代码里,我们会看到 Multi-Head Attention 的计算中,Q 头和 K, V 头数量并不一样,这实际上是 Group Query Attention:多个 Q 会共享相同的 K, V,相比原始的 Multi-Head 这么做能在保持性能的同时有效降低 KV-Cache 的压力。实际上我觉得和巻积里的 Depth-wise Convolution 思路基本是差不多,对 CV 模型比较熟悉的同学肯定很眼熟。
RoPE 位置编码
还有一个值得讲的是 RoPE 位置编码的使用,这里我们暂且按住不表,就暂且简单总结为:
有兴趣的朋友可以先直接参考苏老师在科学空间写的博客:
https://www.spaces.ac.cn/archives/8265
1 | class Qwen3Attention(nn.Module): |
Qwen3MLP
作为 Qwen3 的 FFN,这里基本就是一个门控网络的思路。和前面 Attention 类似,为了利用张量并行,我们将 gate 和 up 两个 Linear 映射的权重网络合并在一起进行计算。同时,对于模型 $SiLU(gate) * up$ 的操作,我们也正好融合为了一个算子 SiluAndMul 一起进行。
1 | class Qwen3MLP(nn.Module): |

说些什么吧!