立志写出让纯夏都能看懂的教程讲解
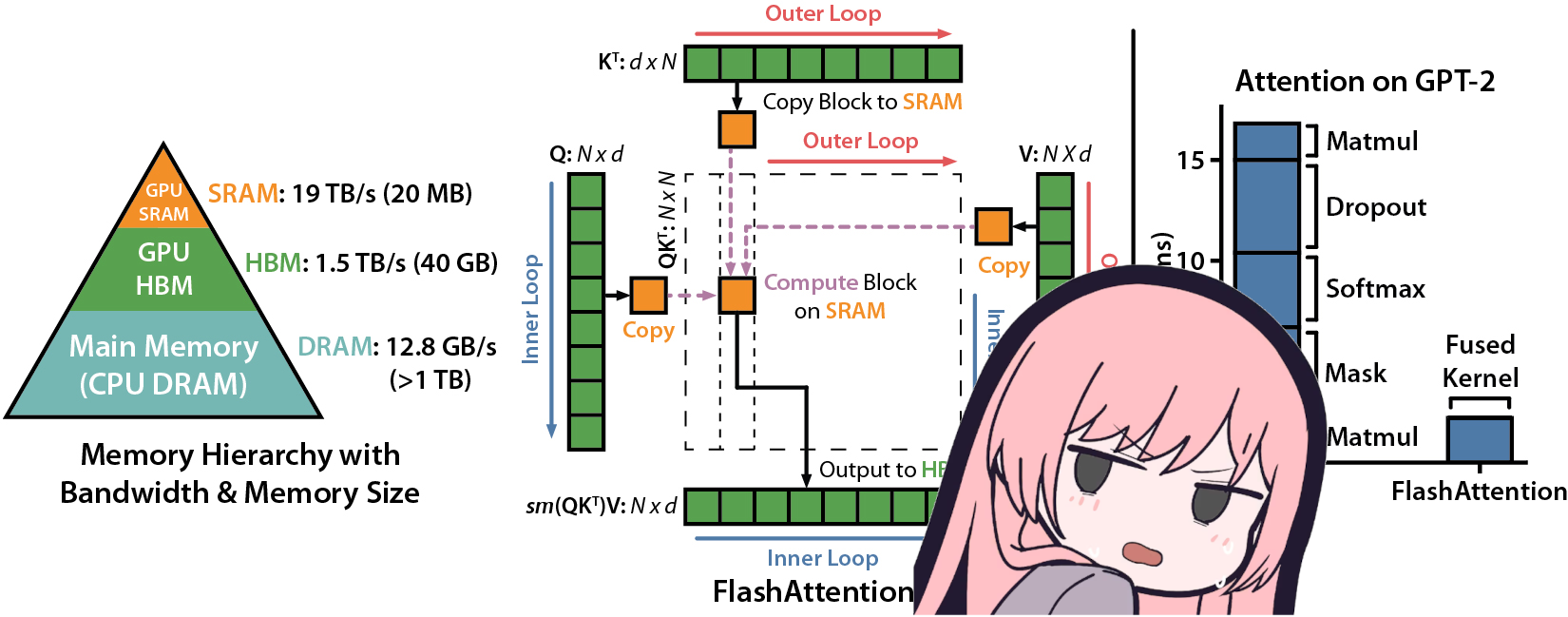
作为 LLM 加速的核心,基本每次都要编译 FlashAttention 库来实现计算加速,足见其应用之广泛,因此专门出一章来学习 Flash Attention 第一版的实现。
我们都知道,Attention 计算是这样的:
$$\text{Attention}(Q,K,V)=\text{softmax}(\frac{QK^T}{\sqrt{d_k}})V $$
在标准的 Attention 实现里,我们一般分成下面三步完成:
$$S=QK^T \in \R^{N\times N} , \quad P=\text{softmax(S)} \in \R^{N\times N}, \quad O=PV \in \R^{N\times d} $$
- 从显存 HBM 中加载 $Q, K$,计算 $S=QK^T$ ,把 $S$ 写回显存 HBM;
- 从显存 HBM 读 $S$ ,计算 $P=\text{softmax(S)}$ ,把 $P$ 写回显存 HBM;
- 从显存 HBM 按 block 读 $P, V$ ,计算 $O=PV$ ,把 $O$ 写回显存 HBM。
从上面的步骤可以看出来,我们计算一次 Attention 都要从 HBM 中取两次大小是 $N\times N$ 的矩阵 $S,P$ ,由于实际 transformer 里序列长度 $N$ 往往是远大于 hidden size $d$ 的,这就导致计算 Attention 时会因为从 HBM 搬运大量数据而浪费时间。换句话说,标准 Attention 的计算在长序列的情况 ( N 远大于 d ) 下会是 IO Bound 的。
如果有过 CUDA 编程经验的同学看到这一定会有一个直观的想法:如果我们能分块计算 Attention,把庞大的输入按块 $Q_b, K_b$ 从 HBM 取到 SRAM (下标 b 表示 block),把结果 $O_b$ 按块存回去,这样减少了频繁从最慢的 HBM 中取数据,那不是能加速整个计算?
恭喜你,你离提出 Flash Attention 1 就差一步了。
从 Softmax 出发
分块计算会有什么难点呢? 让我们重新审视下标准 Attention 的计算流程:
$$S=QK^T \in \R^{N\times N} , \quad P=\text{softmax(S)} \in \R^{N\times N}, \quad O=PV \in \R^{N\times d} $$
emm… $S$ 分块计算就是简单的矩阵分块,$P$ 分块计算的话…
没错,盲生你发现了华点:对第 $i$ 行而言, softmax 计算里分母是需要我们有整行 N 个 key 的 Score 求和,但分块后,我们每次都只能看到 Block 个 Key 的局部和:
$$\text{softmax}(s_{ij})=\frac{e^{s_{ij}}}{\sum_{k=1}^{N}e^{s_{ik}}} $$
好在这个问题也有方法进行解决,那就是 **online softmax。**但在这之前,我们先要了解 safe softmax。
Safe Softmax
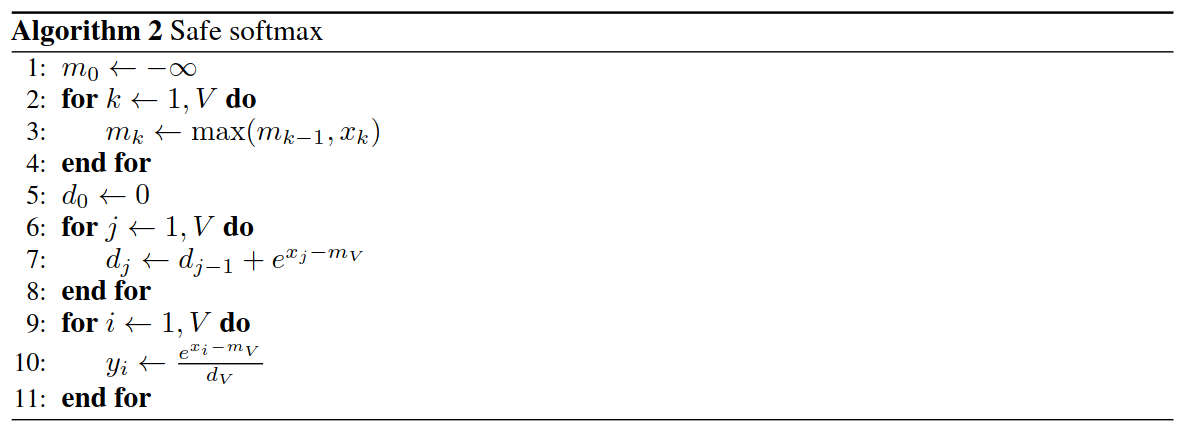
在实际计算里,如果我们使用 native 的计算方法,我们在指数运算的过程中存在不稳定:数值在指数运算容易溢出等。
因此,safe softmax 提出对数组 $x[1…n]$ 的每个元素都减去最大值 max 后,再进行 softmax 计算,也即:
$$y_i=\frac{e^{x_i-\max\limits_{k=1}^N x_k}}{\sum_{k=1}^{N}e^{x_j-\max\limits_{k=1}^N x_k}} $$
如此一来,我们计算的时候需要:
- 遍历数组 $x$ 找到最大值 max;
- 遍历数组 $x$ 减去最大值 max 而后指数求和;
- 遍历数组 $x$ 按元素计算 softmax。
总共是 3 次 load,1 次 store,相比 native 多了一次 load 操作。
online softmax
safe 版本之所以多了一次 load,主要是因为其多了遍历找最大值的步骤。那么,如果我们能随着遍历 “动态更新这个 max” 不就能省去找全局最大的遍历了吗。因此,online 的核心在于我们如何使用动态 max 的同时,在数学上还能保证最后结果等价。
我们直接展示 online 的算法思路:
- 遍历数组 $x$ 维护 $m_j$ 记录到索引 $j$ 为止的局部最大值;同时,记录局部指数和 $d_j$;
- 遍历数组 $x$ 维护 按元素计算 softmax 值
可见,我们只需要 2 次 load,1 次 store。

online 的核心在于:我们终于可以逐块更新最大值 $max$ 和指数和 $d$,并且最后数值和 native 保持一致。怎么证明呢?
换句话说,怎么证明在 online 下,当完成第一次遍历后,我们依然能够有:
$$m_V=\max\limits_{k=1}^Vx_k \quad d_V=\sum_{j=1}^Ve^{x_j-m_V} $$
第一个最大值是显然的,第二个我们用数学归纳就能简单证明:
-
当 $V=1$ 时,显然,我们有:
$$d_1=e^{x_1-m_1}=\sum_{j=1}^1e^{x_j-m1} $$
即,上式对 $V=1$ 成立。
-
我们 假设 当 $V=S-1$ 时,上式成立,即有:
$$d_{S-1}=\sum_{j=1}^{S-1}e^{x_j-m_{S-1}} $$
当 $V=S$ 时,
$$\begin{aligned} d_S &= d_{S-1} \times e^{m_{S-1}-m_S} + e^{x_S-m_S} \\ &= \left( \sum_{j=1}^{S-1} e^{x_j-m_{S-1}} \right) \times e^{m_{S-1}-m_S} + e^{x_S-m_S} \\ &= \sum_{j=1}^{S-1} e^{x_j-m_S} + e^{x_S-m_S} \\ &= \sum_{j=1}^{S} e^{x_j-m_S} \end{aligned} $$
可见,上式依然成立,证毕。
回到 Flash Attention 1
我们在有了 online softmax 的基础知识后,再回头来看最开始卡住我们的地方:
如果我们能分块计算 Attention,把庞大的输入按块 $Q_b, K_b$ 从 HBM 取到 SRAM (下标 b 表示 block),把结果 $O_b$ 按块存回去,这样减少了频繁从最慢的 HBM 中取数据,那不是能加速整个计算?可是,如何解决 softmax 的分块计算问题呢?
现在我们终于可以没有任何后顾之忧的去分块计算 Attention 了。让我们再再再次回顾标准的 Attention 式子:
$$S=QK^T \in \R^{N\times N} , \quad P=\text{softmax(S)} \in \R^{N\times N}, \quad O=PV \in \R^{N\times d} $$
我们将 Q, K, V 沿着 序列维度 $N$ 切成大小为 $B$ 的块:
$$Q=\begin{bmatrix}Q_1 \\ Q_2 \\...\\Q_{T_r}\end{bmatrix} (T_r=\lceil N/B_r \rceil) \quad K=\begin{bmatrix}K_1 \\ K_2 \\...\\K_{T_c}\end{bmatrix} (T_c=\lceil N/B_c \rceil) \quad V=\begin{bmatrix}V_1 \\ V_2 \\...\\V_{T_c}\end{bmatrix} $$
其中,$B_r$ 和 $B_c$ 分别是 Q 和 KV 的块大小(具体取值受 SRAM 大小影响)。
原本 $S, P$ 这些 $N \times N$ 的 Attention 矩阵就被切分成了 $T_r \times T_c$ 个小块,每个小块大小为 $B_r \times B_c$ 。接下来就是对这些 block 做分块的 softmax 计算。
Flash Attention Forward
我们定义:
- 输入:$Q, K, V \in \R^{N\times d}$ 存于 HBM
- 输出:$O \in \R^{N\times d}$ 存于 HBM
- 辅助变量:$\ell \in \R^{N}$ 是 行指数和, $m \in \R^{N}$ 行最大值
Step 0:初始化
$$O=0_{N\times d} \quad \ell=0_N \quad m=(-\infty)_N $$
Step1:外层遍历 KV 块
Line 5 从 HBM 中加载分块的 $K_j, V_j$ ( $\R^{B_c\times d}$ ) 到 SRAM
Step2: 内层遍历 Q 块
Line 7 从 HBM 中加载分块的 $Q_i ( \R^{B_r\times d} ), O_i, \ell_i, m_i$ 到 SRAM;
Line 10 有了 Q, K 块以后,我们能够很快计算这个块的局部 attention score,并使用 Online Softmax 的方法来统计局部最大值 $\tilde{m}_{ij}, \tilde{\ell}_{ij}$;
Line 11 根据局部统计量更新全局最大值:
$m_i^{\text{new}}=\max(m_i, \tilde{m}_{ij})$
$\ell_i^{\text{new}}=\ell_i \cdot e^{m_i-m_i^{\text{new}}} + \tilde{\ell_{ij}}\cdot e^{\tilde{m}_i-m_i^{\text{new}}}$
这里乘以 $e^{m_{\text{old}} - m_{\text{new}}}$ 的核心原理和我们刚刚推导的 Online Softmax 是一样的,实际上你可以把它简单理解为一个换底变换,它把所有以旧 max 为基准的 exp 值统一换算到新 max 基准下。
Line 12 更新输出块 $O_i$ 。这个式子看起来很复杂,实际上就是和前面我们更新 $\ell$ 思路是一模一样的,旧的 $O_i$ 乘以 $\frac{\ell_i \cdot e^{m_i - m_i^{\text{new}}}}{\ell_i^{\text{new}}}$ 把之前以旧 max 为基准的结果修正为新 max 基准,当前块对应的计算则是 $\frac{ e^{\tilde{m}_i - m_i^{\text{new}}}}{\ell_i^{\text{new}}} \cdot \tilde{P}_{ij} V_j$
这里这个更新思路建议大伙重新想想 online softmax 换底的思路。
Line 13 更新全局统计量。

Flash Attention Backward
前面我们一直在提 forward 时的优化,Flash Attention 利用分块的思路避免了存储任何中间结果 S, P 到 HBM 中。然而,当模型 backward 更新的时候,还是需要 S, P 的值来计算梯度。
为了解决这个问题,Flash Attention 采用 recomputation 的思路:
- forward 保存:$O$, $\ell$ (每行的指数和 Softmax 分母), $m$ (每行最大值);
- backward 计算:从 $Q, K, V$ 和 $\ell, m$ 能够非常轻松简单的分块计算出 $S, P$
我们从保存 $S, P \in \R^{N\times N}$ 到保存 $\ell, m \in \R^{N}$ 显存需求直接从 $O(N^2)$ 降低到了 $O(N)$。由于 Attention 计算大多时候是 memory-bound 的,因此这个 trade-off 完全可以接受。

说些什么吧!